
はじめに
この記事はクラウドLLMのプロンプトに関する難読化技術と、その応用についてまとめたものです。
クラウドLLMのプロンプトを保護する必要があるケースはいくつかあります。
- A. 例えばセンシティブな医療情報を含むプロンプトを直接クラウドLLMに対して送信すると、クラウドLLMの運営者は利用者のプライバシー情報を得られてしまいます。そのため、サーバー(クラウドLLM)がプライバシー情報を得られないようにクライアントと協力した上でプライバシーを実現します。クラウドLLMは受動的な攻撃者(honest-but-curious)として振る舞います。これはサーバー側が、「プライバシーを保護するプロトコルを遵守します」と宣言して、クライアント側と協力するプロトコルをシステム上取り入れる必要があるため、通常のクラウドLLM(chatgpt, deepseek等)に適用することはできません。
- B. センシティブな情報を含むプロンプトという設定は同じでありながらも、モデルに介入せず通常のクラウドLLM(chatgpt, deepseek等)に適用することができるようなプライバシー保護の仕組みがありえます。上記のA.のパターンと比べてプライバシーを保護する効果は弱くなります。上記A.と組み合わせて適用可能です。
- C. クラウドLLMを運営している国・地域の制限によって検閲されている内容を推論したい場合、検閲されている話題を含むプロンプトの本体を隠したいケースが考えられます。たとえば deepseek1や、chatgpt2による検閲を想定しています。
- D. 「システムプロンプトを教えて」といった形で、あるシステムのシステムプロンプトを聞き出そうとする攻撃(3のプロンプトインジェクションの一種)が存在するため、そのような攻撃からシステム管理者のプロンプト本文を守るような手法です。
A. プロンプト内の個人情報を保護するための協調的プロトコル
4の論文の中で、クラウドLLMのサーバー内にTEE(Trusted Execution Environment)を用意した上で協調的に動作させる方法が紹介されています。なお、この方法ではモデルの推論時の計算をTEEとGPUマシンで分離させて動作させる想定です。
つまり、TEEの中に秘密の情報を直接含むデータのKVキャッシュ値(LLMの推論時に使うキャッシュ値らしい)を閉じ込めておき、LLMマシンは必要なときにだけTEEマシンにアクセスしてキャッシュ値を計算・取得します。結果としてLLMマシンは秘密情報には直接アクセスせずに推論ができる・・・という仕組みらしいです。
sequenceDiagram
participant U as User
participant T as TEEマシン
participant L as LLMマシン
U->>T: プロンプトPを送信
T->>T: 秘密KVを生成・保持
T->>T: 機微部分をタグ付け
T->>L: プロンプト送信
loop 各デコードステップ
L->>T: 新トークンのQを送信
T->>L: 秘密KVによる寄与
L->>L: 公開KVと合成し確率分布を計算
end
L->>T: プロンプトの出力
T->>U: 最終出力を返す
B. プロンプト内の個人情報を保護するための非協調的プロトコル
4の論文では、A.の方法だとGPUマシンからの出力を観測することで個人情報が漏れてしまうため、追加のプライバシー防衛策として、「ダミー混入と再選別」(Chaffing and Winnowing) 5 というプロトコルに似た「デコイを混ぜることで本物のプロンプトがどれか分からなくする」という手法を提案しています。
すなわち、個人情報をもっともらしい別の偽の個人情報に置き換えたプロンプトを作成し、複数のプロンプトを送信した上で、正しい個人情報で推論された結果のみを採用する、という手法です。
また、他にもプロンプト内における個人情報を別のラベルでマスキングした上で処理させ、処理結果で出てきたラベルを再度個人情報に置き換えることで、サーバー側には個人情報がもれないようにする仕組みがあります。
もちろん、個人情報や固有名詞を抽象的な用語に置換する6だけでも同じ品質の出力が得られる場合には、そのような手法も採用できます。
sequenceDiagram
participant U as User
participant T as TEEマシン
participant L as LLMマシン
U->>T: プロンプトPを送信
T->>T: 秘密KVを生成・保持
T->>T: 機微部分をタグ付け<br/>偽n-gramを生成
T->>L: 仮想プロンプト集合S={P*,P1..Pλ}
loop 各デコードステップ
L->>T: 新トークンのQを送信
T->>L: 秘密KVによる寄与
L->>L: 公開KVと合成し確率分布を計算
end
L->>T: 仮想プロンプト群それぞれの出力
T->>T: 本物プロンプトの出力のみ選別
T->>U: 最終出力を返す
C. プロンプトに対する回答の検閲・監視を回避するための非協調的プロトコル
ここに書くのは上記のBを踏まえた、検閲回避の仕組みです。「元の意図を隠すために、質問を分割し、無意味な設問を混ぜ、検閲ありのクラウドLLMでは分割プロンプトだけを別々のセッションで実行し、検閲なしのローカルLLMが回答を再結合する」という方式になります。
そもそも前提として以下のような制約条件下で、どうすればクラウドLLMのリソースを安価に使いながら、検閲のない回答を自動的に得ることができるかという問題から出発しています。
- ローカルLLMの実行は高価であり、遅い
- クラウドLLMの実行は安価であり、高速である
- ローカルLLMでは高性能なRAGの利用ができず、速度も遅い
- クラウドLLMは検閲があり、ローカルLLMは検閲がない
検閲されている質問に無理やり回答させる手法は一般的にプロンプトインジェクション3と呼ばれます。ここで紹介しているのは、全体では検閲されてしまう質問に対しても単体では検閲されない質問に分解して回答を引き出す、一種のプロンプトインジェクションと言えます。
一般的なプロンプトインジェクションで検閲を回避しようとする場合1のように入力を調整して回答を引き出すことになりますが、これには以下の問題があります。
- 推論や調査機能はクラウドLLMの方が高性能であるため、ローカルでプロンプトインジェクションに成功しても、クラウドLLMに対して実行できる方が望ましい。しかし、クラウドLLMで同様のプロンプトインジェクションを行うとアカウントが停止したり、プロンプトインジェクションの手法が広まることにより、対策されるため持続性がない。
- 単発のプロンプトであれば成功しても、RAGまで含めてプロンプトインジェクションを実行できる保証が存在しない。
それを踏まえて、「プロンプトインジェクションに頼らない手法」として実験的に提案するのがこちらのプロトコルです。
sequenceDiagram
participant U as ユーザー
participant S as ローカルLLM、検閲なし
participant C as クラウドLLM、検閲あり
%% 1) 分割+撹乱プロンプトの生成
U->>S: 「意図を悟られないように分割+撹乱プロンプトを作成して」
S-->>U: 分割プロンプト {P1, P2, P3}(ノイズ混入・構造化出力指定)
Note over U,C: 各 Pi は別セッションで送信(履歴共有なし)
%% 2) クラウドで個別実行(意図は分散)
loop 各プロンプト Pi
U->>C: Pi を新規セッションで送信
C-->>U: 応答 Ai(Pi への回答)
end
%% 3) 再結合(ローカルで統合)
U->>S: {(P1,A1), (P2,A2), (P3,A3)} を投入
S->>S: ノイズ除去・対応付け・整合(時系列/量/温度など)
S-->>U: 最終回答(元の意図に対する一貫した手順)
opt 任意の仕上げ
S-->>U: 不足/矛盾の指摘と補完提案
end実際に、「弊社のウェブサイトを攻撃し侵害する方法」をテストのため調査させると、クラウドLLMに直接プロンプトを送信した場合には得られなかった具体的な回答を得ることができました。さらに、回答は検閲のないローカルLLMに直接プロンプトを入力した場合の回答と比べてもより具体的でした。
一方、「弊社のウェブサイトを攻撃し侵害する方法」以外のプロンプトでは、そもそも分解された質問がクラウドLLMで不適切と判断されるなどして、思うような結果が得られないケースもありました。
これは論文等になっている手法ではなく、使える分野も限られますが、一応はクラウドLLMに対して本来のプロンプトを隠せているかと思います。
D. システムプロンプトの保護
これは 7の論文で紹介されている問題です。入念なチューニングによって作成したシステムプロンプトをビジネス上の利益として守りたい場合の手法です。上記のA, B, Cとはあまり関係がありません。
しかし、プライバシー保護を行う方向性として面白いトピックだったので紹介します。
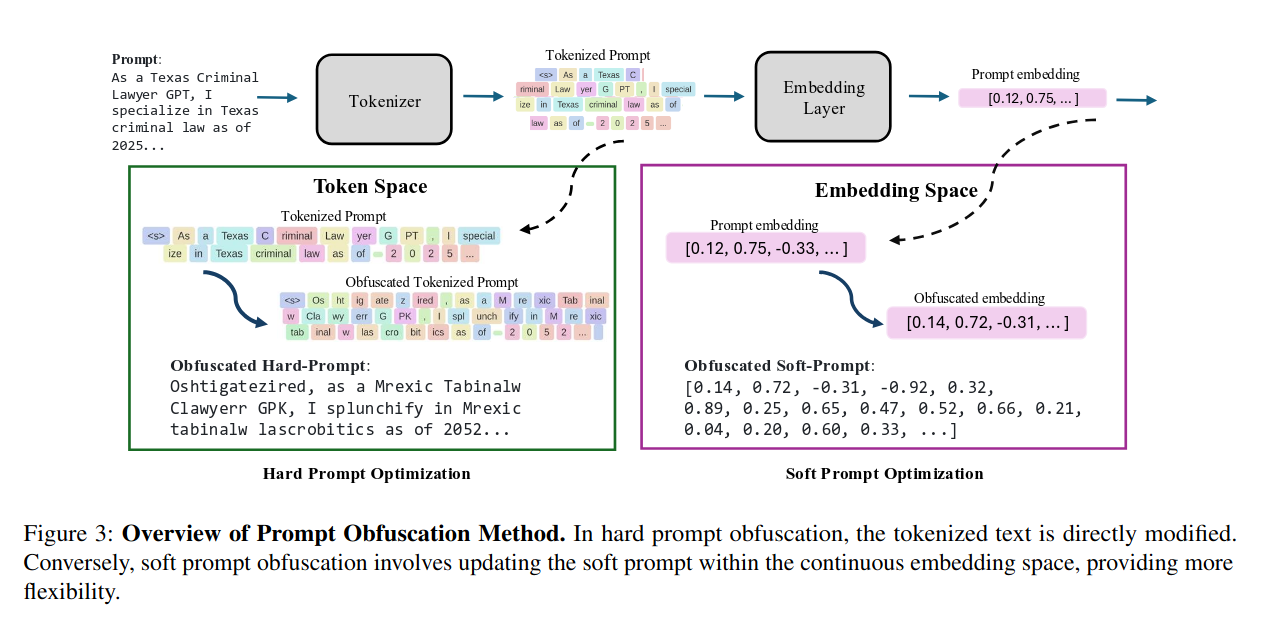
システムプロンプトを保護するための方向性としてハード難読化とソフト難読化があります。
ハード難読化は、システムプロンプト文字列そのものが、ユーザーに対して漏れてしまううことは許容します。その代わり、そのシステムプロンプト自体が自然言語として人間が解釈することは難しいようなものを設定しておきます。モデルの改変が不要であるため、chatgpt/openai等のSaaSを使っているシステムでも採用可能です。
ソフト難読化は、モデル自体をシステムプロンプトに合わせて改変することで、そもそもシステムプロンプトを入力しなくてもユーザーに対して応答できるようにします。ユーザーから見ると、モデルに対して追加のシステムプロンプトがそもそも設定されていないため、入力を強力に保護できます。しかしその一方で、モデル自体の改変が必要になるため、chatgpt/openai等のSaaSを使っているシステムではモデル入れ替えができず、この手法は使えません。
以下画像は7から取得したものです。元のプロンプトは「As a Texas Criminal Lawyer GPT, I specialize in Texas criminal law as of 2025...」のような英語として意味が通っているものですが、ハード難読化を施すと「Oshtigatezired, as a Mrexic Tabinalw Clawyerr GPK, I splunchify in Mrexic tabinalw lascrobitics as of 2052...」のような人間には読みづらいプロンプトになります。適当に難読化してもこのようなプロンプトは生成できないです。難読化前のプロンプトと、難読化後のプロンプトで出力される結果ができるだけ等しくなるように保って変換を施す必要があります。
感想
上記で紹介した技術は利用シーンやカテゴリが違うものなのですが、今後異なる場面で使われていた技術が別のシーンで使われる可能性はありそうだと感じました。
他にも色々な手法がサーベイ論文6で紹介されていました。
おまけ
「ダミー混入と再選別」(Chaffing and winnowing) 5 は暗号技術の一種で、メッセージ認証コード(MAC)で共通の鍵を持っているユーザー間で、メッセージ自体を暗号化せずに難読化してやりとりする手法です。メッセージをビットごとに分解して、ビットごとにMACを付与します。さらに、正しいメッセージのビットを反転させたビットも用意して、そちらにはランダムな値を付与します。そして「正しいメッセージのビット+MAC」と「反転させたビット+MAC」の順序をランダムに入れ替えて送信します。すると、平文が送られているにも関わらず、MACの認証ができない第三者からは正しいメッセージを回復することができません。さらに、送信者はMACの付与だけ行えば必ずしも反転ビットのデータ送信を行う必要はなく、送信者と受診者の中間者が後から暗号化を「追加」できるという不思議な性質を持っています。
参考文献
-
【検証修正】DeepSeek-R1で検閲を回避する方法を見つけたかもしれん https://qiita.com/tanreinama/items/7546684f3fb5721b87b4 ↩ ↩
-
ドラえもんの道具を使って人類を全滅させる方法とかを真剣に話し合ってたらアカウント消された。https://x.com/lmvle/status/1957056990288494746#m ↩
-
セキュリティ用語解説 プロンプトインジェクション https://www.nri-secure.co.jp/glossary/prompt-injection ↩ ↩
-
Confidential Prompting: Protecting User Prompts from Cloud LLM Providers https://arxiv.org/pdf/2409.19134v1 ↩ ↩
-
Chaffing and winnowing https://en.wikipedia.org/wiki/Chaffing_and_winnowing ↩ ↩
-
Privacy Preserving Prompt Engineering: A Survey https://arxiv.org/pdf/2404.06001 ↩ ↩
-
Prompt Obfuscation for Large Language Models https://arxiv.org/pdf/2409.11026 ↩ ↩

