
はじめに
本記事ではSimulated Blockchains for Machine Learning Traceability andTransaction Values in the Monero Networkの解説を行います。
まず本研究の目的と方法を説明し、シミュレーションするシナリオ、特徴量、予測方法とその結果について述べ、最後にまとめを書きます。
本研究の目的と方法
Moneroは匿名性を重視した仮想通貨で、リング署名と呼ばれる署名方式を用いて、トランザクションの送金元と送金額を匿名化し、ステルスアドレスにより送金先を匿名化する。
整理するとMoneroのブロックチェーン上では以下の特徴がある。
・受取人のアドレスが含まれない
・トランザクションの取引量が匿名化される
・Inputになりすまし取引であるRingCTが混じっていて、Inputが匿名化されている
本研究では機械学習を用いて、Moneroの匿名性を排除するのが目的である。
そのために、まずタイムスタンプやInputの数、RingCTのサイズ、トランザクション間の接続性など、ブロックチェーンのトポロジカルな側面を定量化する。
なお、サイバーセキュリティの研究では、脅威の開発と評価のために合成データセットを生成することが一般的なので、本研究でも10人および50人のネットワークを含むテストネットワークを作成し、得られたデータセットに対して機械学習による分析を行う。
結論から言えば、本研究の結果、本研究で採用された特徴量のみから機械学習により非匿名化を行うことは困難であることが分かった。匿名性が堅牢であるため、非匿名化のためには今後より多くの特徴量が必要になると思われる。
シミュレーション
複数のエージェントが互いに取引し、同時に採掘するMoneroの経済をシミュレートするために、1台のマシンで複数の端末セッションを作成・管理するアプリケーション「tmux」を使用する。
このネットワーク上で、各エージェントはマイニングと、ウォレットのリモートプロシージャコール(RPC)を実行する。
また、エコノミーファイルは、トランザクションの量、宛先アドレス、金額、トランザクション間の待ち時間などを指定するファイルで確率的に生成される。
Pythonプログラムを使って、これらのファイルを処理し、それに応じて、MoneroウォレットのRPCにHTTPベースのトランザクションリクエストを行う。
トランザクション間の待ち時間は遅延を抑えるのに十分でなければならないという制約のみ課されている。
この研究では、前提条件を変えた複数の経済シナリオ(テストネット)を作成し、それに合わせてエコノミーファイルを作成する。
5つのシナリオのうち3つは10個のエージェントがいる経済で、残りは50個のエージェントがいる経済である。また取引間の待ち時間と取引金額は、ポアソン分布によって生成される。
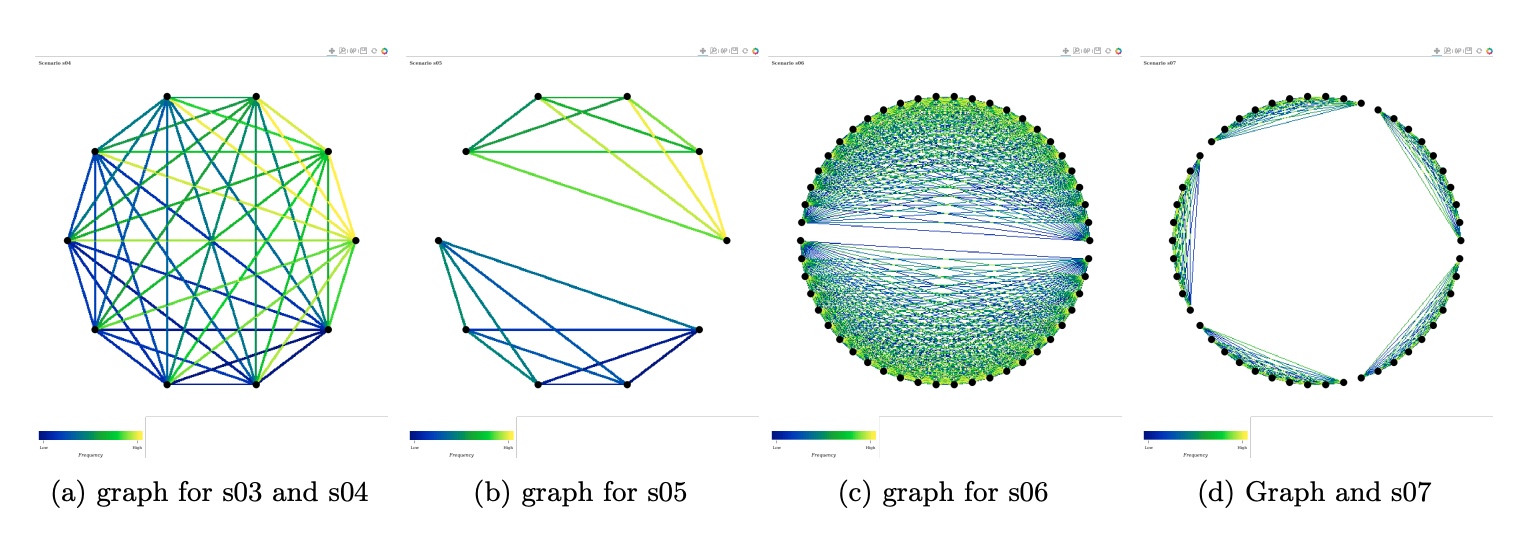
エージェント数はs03,s04,s05では10で、s06とs07では50である。
上図の左のシナリオから説明する。
s03では、待機間隔は、45 から 90,000 の範囲でポアソン・パラメータを変化させたものである。
一方、取引金額は全エージェント共通のポアソンパラメータから算出される。
s04では、取引金額の生成にもポアソンパラメータを変化させる。
s05はs03と待機間隔と取引量の条件は同じであるが、経済が2つのプールに分けられ、エージェントは自分が所属するプール内でのみ取引を行う。
公開された取引データに基づいてこれらのプールを識別することは、我々が追求する機械学習の問題の1つである。
s06では、同数のエージェントからなる2つのプールを作成する。さらに
2つのプールに対して2つの異なるトランザクションのサイクルを作成し、現実の時間帯の違いをシミュレートする。
s07は、5つの10エージェントからなる取引ネットワークである。
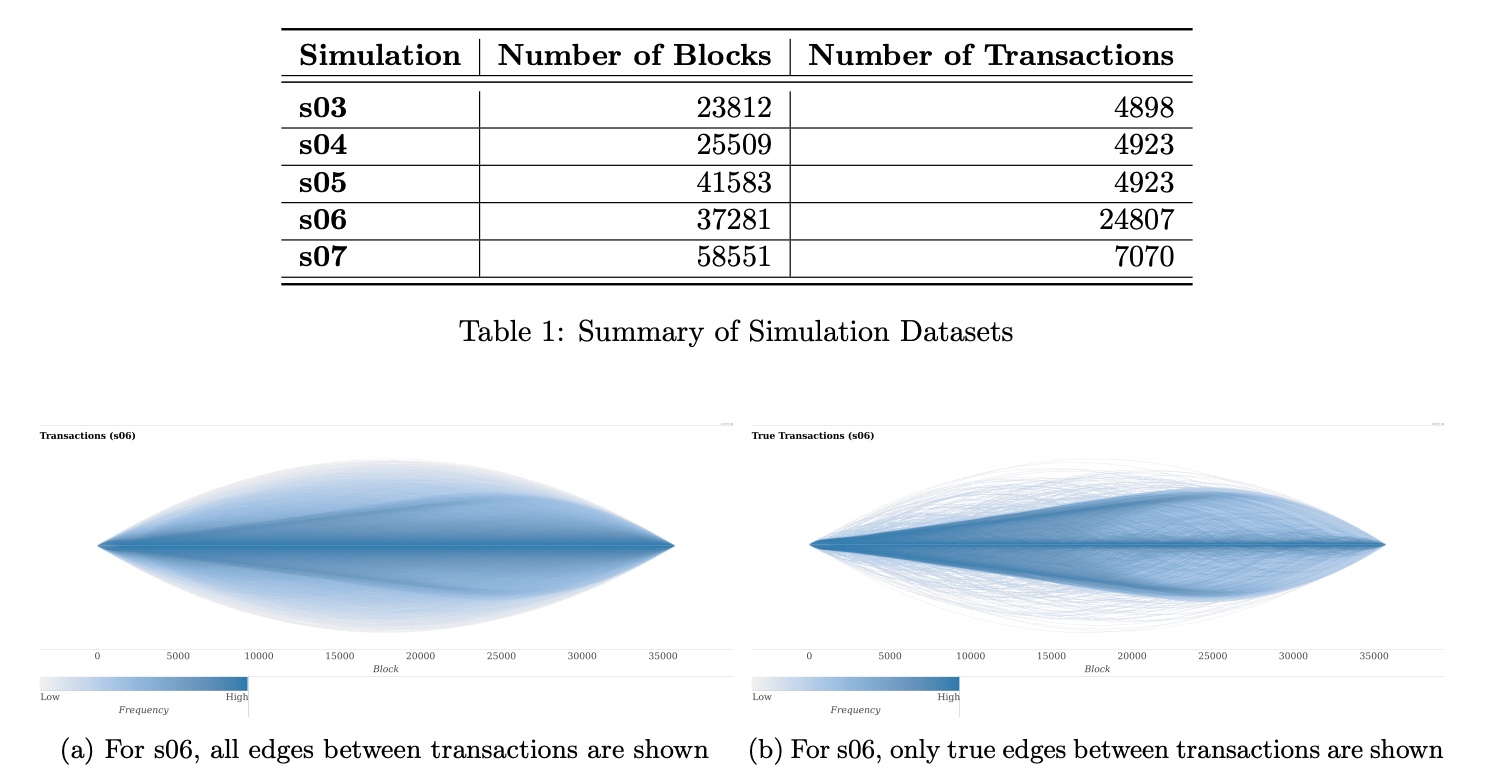
上図は、各シナリオのブロックチェーンから、なりすまし取引(RingCT)を削除する前後で得られるブロックチェーン上での取引を示すネットワーク図である。
特徴量の加工
実際の暗号通貨ブロックチェーン上のほとんどの機械学習による分析では、教師あり学習のためのラベルを入手することが困難で、Moneroの場合も同様である。
本研究では、Shapeshiftサービスの取引データを活用する。このデータセットでは、約1,700,000件の取引エントリーのうち、20,000件はMoneroに変換されるShapeShiftの取引である。
各トランザクションの項目に対して、Moneroのエクスプローラーインターフェースに表示される、トランザクションのタイムスタンプ、リングサイズ、曜日、時間など7つの0-hop特徴(その取引に固有な特徴)量が含まれている。
それらの0ホップ特徴量と175の1ホップ特徴量から、平均、最大、標準偏差などそのトランザクションに関する基本統計量と
そのトランザクションの近隣の0-ホップ特徴量に関する情報も収集し、Z正規化する。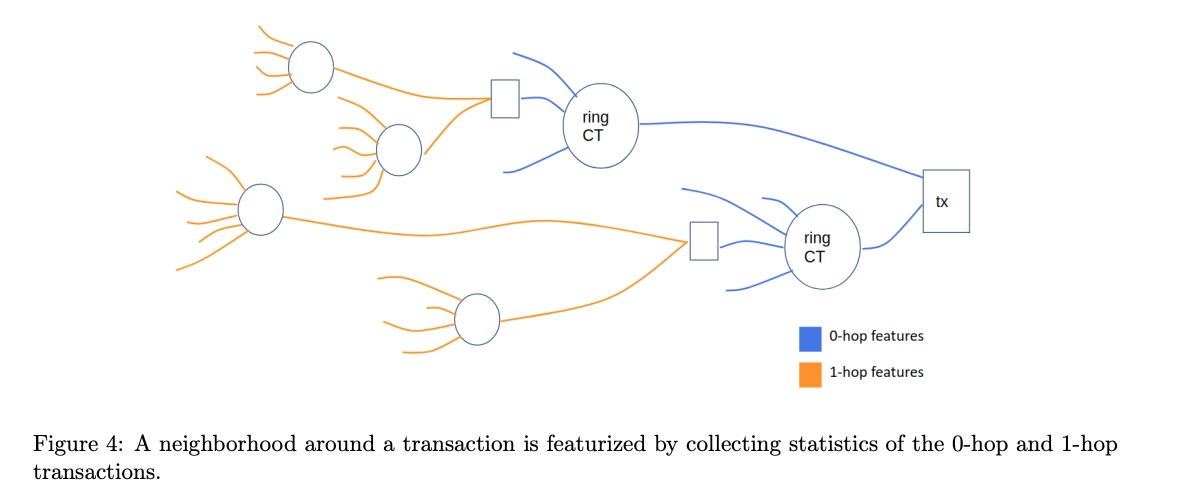
この方法により、ネットワーク全体を抽出せずに特定のトランザクションの近隣情報を考慮することができる。
Shapeshiftのトランザクションの予測に1ホップ情報が有用であることと、テストネットでのグループのメンバー予測と取引額予測には近隣情報が有用であることが判明した。
また5つのテストネットで取引額の予測を行い、s05, s06, s07ではグループのメンバー予測を行う。
予測
なりすまし取引か否か
まず、RingCTのうちどれが実際の直前のトランザクションなのか予測する。
この予測により、ユーザーの典型的な取引時間帯など、真のInputに関する情報を明らかにすることができる。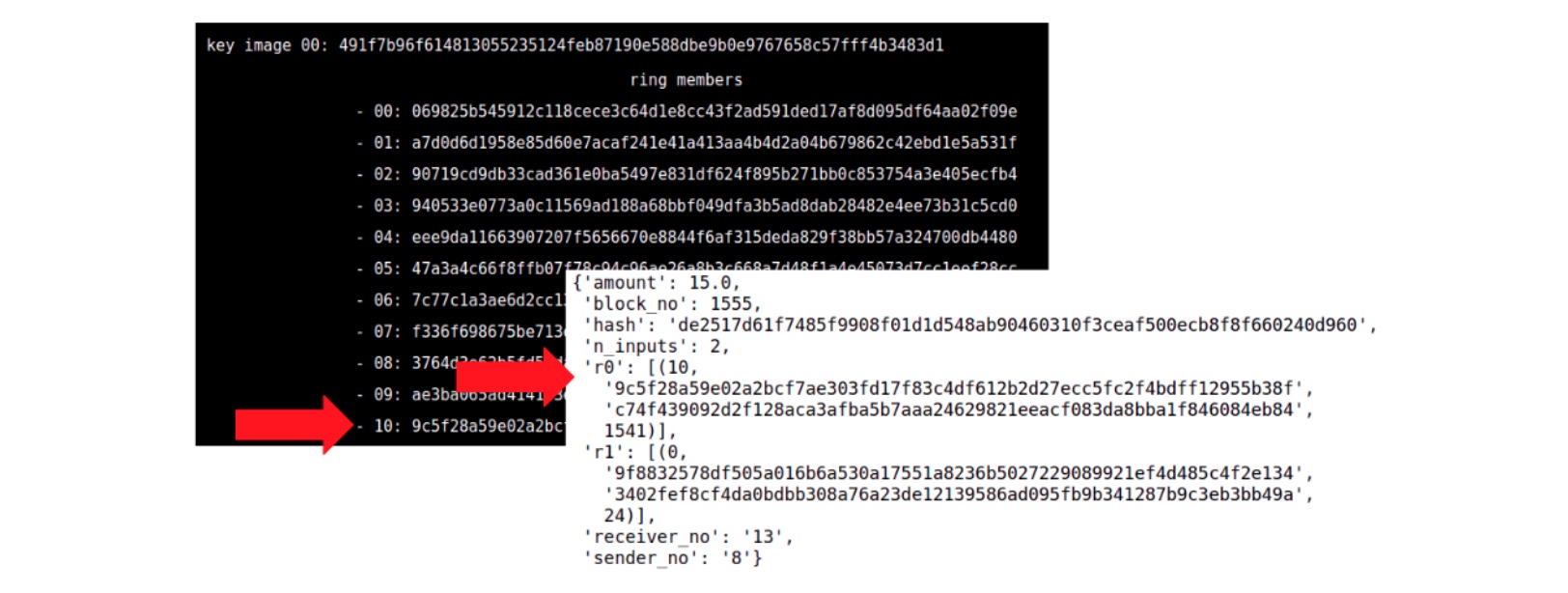
黒い画像がブロックチェーンのスクリーンショットで、白い画像が示すユーザーのウォレットを分析することで、赤い矢印が指す実際の直前のトランザクションを予測する。
ユーザーとグループメンバーの予測
次にトランザクションログからユーザーとグループを特定するタスクでは、ニューラルネットワークとランダムフォレストを使用する。
この場合の観測データはトランザクションで、そのトランザクションの受信者が所属するグループを分類する。
シナリオ中のグループは、指定された時間帯にのみ、グループ内でのみ一定の時間間隔で取引する。
この時間間隔は、タイムゾーンに似た周期的なパターンで繰り返される。
両モデルとも、ハイパーパラメータのチューニングにはランダムサーチが用いられた。
ランダムフォレストは解釈可能な特徴の重要度の順位を持つため、グループメンバーの予測に有益な特徴のトップ3はシナリオ毎に以下のようになった。
・S05では、トランザクションのInputのうち、入力分量に関係するものである。
重要度の高い順に並べると、平均入力分数(minutes)の合計、最大入力分数(minutes)の平均、最小入力分数(minutes)の平均値。
・S06では、重要度の高い順に並べると、入力秒数の総和、最大入力時間の平均値、および最大入力時間の合計。
・S07では重要度の高い順に並べると、入力分の和の中央値、入力分の最大値、入力分の最大値の平均値。
※おそらく上記は有用な情報を何も得られていないまま無理やり順序を付けた特徴量であると思われる。
以上の予測結果

シナリオs06,s07での予測の不調の要因は、ユーザー間の均一性と設計仕様に比べ、トランザクションの投稿時間のタイムラグが大きかったことである。
※当てずっぽうで予測しても、例えば2グループからの所属グループ予測では50%になることに留意せよ。
取引金額の予測
この予測の当てはまりの良さを測るのに、決定係数R^2=1-\frac{\sum_i\lparen y_i-\tilde{y}\rparen^2}{\sum_i\lparen y_i-\bar{y}\rparen^2}を用いる。なお、y_iは実際の値、\tilde{y}は予測値、\bar{y}はy_iの平均である。
モデルの予測精度を向上させると0{<}{R^2}{\leq} 1になり、R^2が1に近いほど当てはまりが良いことを表す。
予測にはサポートベクター回帰とニューラルネットワークを用いる。
ハイパーパラメータをランダムサーチによりチューニングした結果、サポートベクター回帰モデルではR^2値が-0.16、ニューラルネットワークは-0.1と0を下回った。
このことから、予測精度の向上のために
- 複数のリングがある場合、リング間の入力レベルの相関を取り入れること
- 既知のユーザーレベルの情報を取引額予測の説明変数に取り入れること
が必要で、取引に関するより多くの情報が必要であることがわかった。
まとめ
この論文では、Moneroのトランザクションの機械学習による非匿名化が上手くいかないことが実験的に示されました。
機械学習による攻撃というテーマを読んだのが初めてだったので、興味深かったです。
参考文献
位相的データ解析によるビットコインブロックチェーンにおけるランサムウェアの検出・・・本研究の分析方法等をより数学的に詳述し、ランサムウェアの検出を行うという論文です。
Moneroのリング署名。理論を噛み砕いて実装。・・・Moneroの署名方式を詳述したブログ記事です。

